With help from AI, microservices divvy up tasks to improve cloud apps
By Melanie Lefkowitz
Cloud applications – widely-used software programs like search, email and social networks – traditionally have relied on large collections of code known as monoliths, which operate as one big application.
As applications grow more complex and our demands on them increase, these monoliths become too unwieldy. Now, companies including Twitter, Amazon and Netflix are turning to microservices – scores of small applications, each performing a single function and communicating over the network to work together.
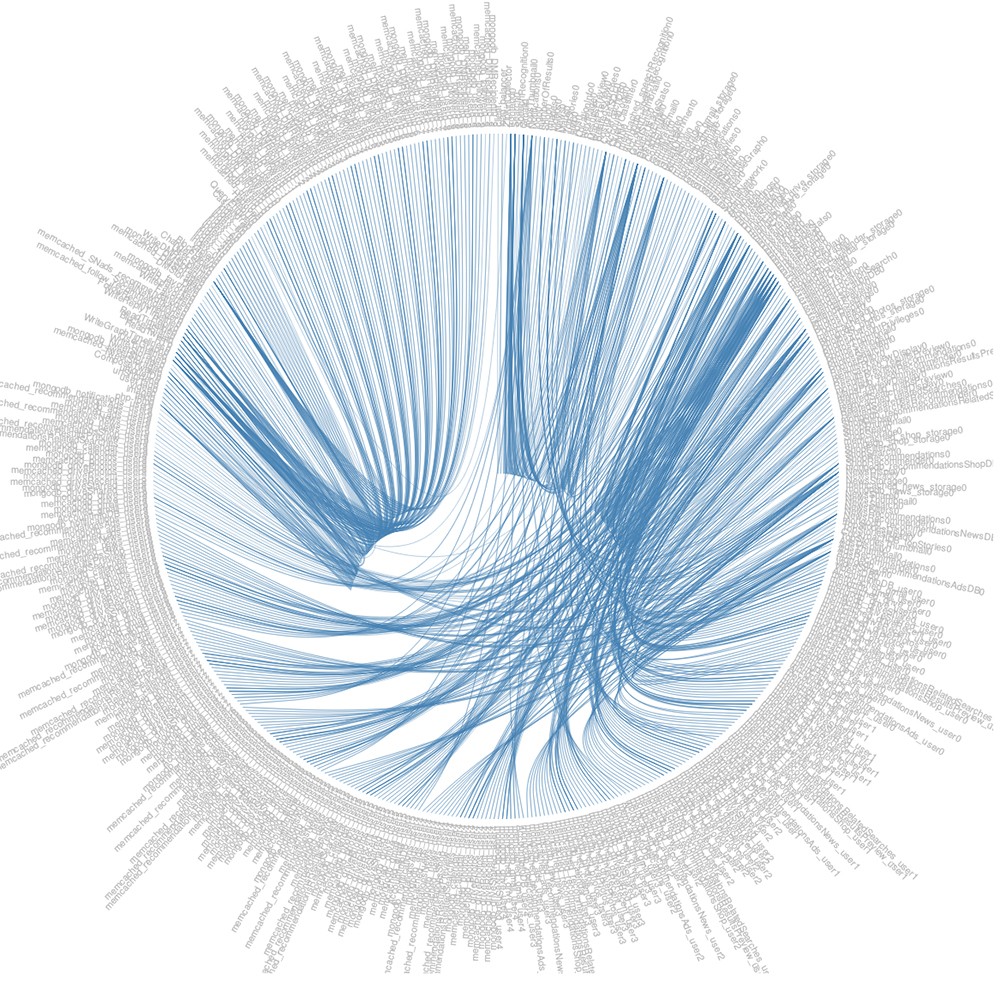
A graph showing interrelationships among microservices – known as “death star graphs” for their resemblance to the Death Star from “Star Wars.”
But even though experts believe a shift to microservices is inevitable, most cloud hardware and software is still designed for monoliths, and most computer science research ideas are still tested on them. To close this gap, a Cornell team led by Christina Delimitrou, assistant professor of electrical and computer engineering, created DeathStarBench, an open-source suite of microservices available to researchers from industry and academia.
“Most research papers still use monolithic applications for their evaluations, which is problematic because the conclusions they come to don’t reflect the behavior of real applications,” said Delimitrou, senior author of “An Open-Source Benchmark Suite for Microservices and the Hardware-Software Implications for Cloud and Edge Systems,” which will be presented at the ACM International Conference on Architectural Support for Programming Languages and Operating Systems (ASPLOS), April 13-17 in Providence, Rhode Island.
“Because there has been this significant change in the way cloud applications are designed, we wanted to explore the implications this change has in hardware and software,” she said. “For that you need representative, end-to-end applications that are built with microservices. Given the lack of such open-source applications, we built this benchmark suite.”
First author of the paper is Yu Gan, a doctoral student in electrical and computer engineering; 22 other Cornell students contributed.
DeathStarBench is named after the graphs that visualize the complicated interrelationships between microservices, which resemble the Death Star from “Star Wars.” The suite includes a social network, a media service, an e-commerce site, a banking system and “internet of things” applications (which allow objects to send and receive data) for coordinating swarms of drones in scenarios such as disaster recovery.
Other universities and large companies are already doing research with DeathStarBench, which was released informally in December and will be officially launched in April.
Microservices make it easier to deploy a complex system, Delimitrou said. For example, if developers want to change one feature in an application, they can update a single microservice instead of grappling with the entire thing. Developers can also use a variety of programming languages that are best suited for specific functions, rather than trying to accommodate an array of tasks with a single language.
There are also disadvantages: Because each microservice performs only one function, the nodes need to communicate with each other quickly and frequently, slowing or potentially overwhelming the network. The interrelationship of those microservices is also too complex for humans to manually navigate, requiring automated, machine learning approaches.
To this end, in related work also being presented at ASPLOS, Delimitrou and her team developed a system that uses machine learning to predict underperforming microservices in a large cloud, such as user requests that take too long.
Waiting until problems occur to fix them can take several minutes, slowing down the entire application. Delimitrou’s method instead uses a deep neural network, trained on the application’s behavior in the past, to anticipate the probability for underperforming microservices in the near future. Detecting such issues early enough allows the system to avoid bad performance altogether, instead of trying to correct it after the fact.
“It’s actually surprisingly effective, not only in finding scheduling issues but finding application bugs, as well,” she said. “We have professional developers managing these applications right now, and even they weren’t able to find some nuanced bugs that the machine learning system found, because it kept seeing some clusters of microservices having issues over and over.”
Another issue in building microservices is finding the proper balance in dividing labor. If developers create too many microservices, the application could end up spending most of its time processing network requests than performing its actual function.
The microservice model “is not strictly better. It has advantages and disadvantages,” Delimitrou said. “But it’s the only way to manage complexity, so going back to monolithic designs is not a feasible path. At the same time, the way we design servers and software today is not suitable for these kinds of applications, which require revisiting the entire system.”
The work was supported by the National Science Foundation, a Facebook Faculty Research Award, a VMWare Research Award, a John and Norma Balen Sesquicentennial Faculty Fellowship and donations from Google Compute Engine, Windows Azure and Amazon EC2.
Media Contact
Get Cornell news delivered right to your inbox.
Subscribe